
The most diverse of all human genes encode a set of proteins at the frontline of our immune system. Many different Human Leukocyte Antigen (HLA) proteins are encoded by genes clumped together in one portion of the human genome known as the major histocompatibility complex region. HLA proteins sit on the surface of cells and bind the chopped-up fragments of other proteins (antigens), presenting them for inspection by immune cells. If the presented antigens are recognized as foreign, the immune system may be triggered to attack, whether the invaders are pathogens, cancer cells, or transplanted tissue.
Remarkably, most HLA genes have dozens, or even hundreds of alleles present in the human population, so across the genome region as a whole there are thousands of different alleles. This variation can affect individual susceptibility to infectious and autoimmune diseases, and is of great interest to geneticists studying human evolution and population history.
But despite the functional and evolutionary importance of HLA genes, sequencing data from this region is biased in many population genomics studies. As a consequence, the results from this region are often treated as suspect, and in many cases are discarded from subsequent analyses.
The reason is that it’s difficult to make sense of HLA data generated by the next-generation sequencing (NGS) methods that are now standard for population genomics studies. NGS methods generate short sequence reads, and when these reads come from highly polymorphic genes like the HLA genes it can be challenging to correctly align them to the genome reference sequence. This problem is even worse when the gene is just one of a group of related polymorphic genes, as is the case for many of the HLA loci.

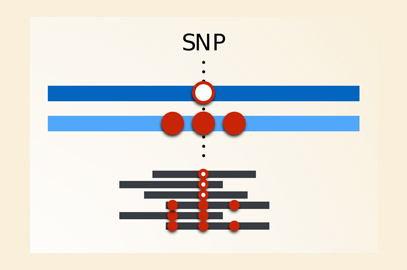
Genotyping errors for a highly polymorphic gene: The left hand side represents a case where sequence reads come from an individual who is heterozygous at a SNP, but where the rest of the gene is relatively similar to the reference for both haplotypes. The reads from both haplotypes can be aligned to the reference, and the SNP genotype is “called” (i.e. determined by the analysis software) correctly. The right hand side represents a case where one of the haplotypes is different to the reference sequence at more than one position. Reads from this haplotype won’t align with the reference and the genotype will be incorrectly called as homozygous at the SNP of interest. Image credit: Vitor R. C. Aguiar.
Though HLA loci are the worst-case scenario for this problem, other examples of polymorphic genes that come in related groups might suffer similar issues (such as the killer-like immunoglobulin receptor (KIR) and olfactory receptor genes). But because the degree of polymorphism in other gene families is less extreme than in the HLA genes, the analysis issues may be less obvious and therefore less likely to be accounted for.
In the latest issue of G3, Brandt et al. demonstrate the scale of the challenge using HLA data from the 1000 Genomes project, which is a collection of high-coverage exome and low-coverage whole-genome sequences from 1092 people generated by NGS. The authors compared the NGS data to a parallel dataset in which 930 of the samples from the 1000 Genomes project were re-sequenced using the “gold-standard” of Sanger sequencing, which doesn’t suffer from the same problems of short read alignment (the Sanger data were generated by Gourraud et al.)
Using the Sanger data as a benchmark, Brandt et al. showed that approximately 19% of single nucleotide polymorphism (SNP) genotypes for HLA genes in the NGS data were incorrect. And around a quarter of HLA SNPs had allele frequency estimates that differed between the two datasets by more than 0.1, with a bias towards overestimation of allele frequency in the NGS data. They also found that the most “unreliable” SNPs in NGS data were those with the highest heterozygosity. In other words, the SNPs at which people were mostly likely to be heterozygous were those that were most difficult to genotype correctly.
The results also suggest the NGS problem probably can’t be solved by boosting the intensity of sequencing efforts (i.e. increasing coverage). Rather, the authors’ argue that better computational analysis is the way forward. For example, they suggest that a major part of the problem is that standard approaches align reads to a single reference sequence. For HLA genes, and perhaps other polymorphic genes, alignment to a database of multiple reference sequences (for example, Boegel et al. and Dilthey et al.) can greatly improve genotyping accuracy by accounting for the different alleles possible at each gene.
A computational fix would be a boon to the many genetic studies that currently struggle to characterize HLA sequence data, including efforts to seek disease associations, quantify gene expression changes, and examine population histories. After all, the diversity of HLA genes is not only a technical challenge, but also a mark of their profound importance to immune system function and human survival.

Genotype mismatches between the 1000 Genomes (next-generation sequencing) and PAG2014 (Sanger sequencing) datasets. Results per polymorphic site (“Position”) and per individual. Dark squares indicate mismatches between genotypes in the two datasets. From Brandt et al.
CITATION:
Brandt, D.Y.C, Aguiar, V.R.C., Bitarello, B.D., Nunes, K., Goudet, J., & Meyer, D. (2015). Mapping Bias Overestimates Reference Allele Frequencies at the HLA Genes in the 1000 Genomes Project Phase I Data
G3: Genes|Genomes|Genetics, 5(5):931-941 doi: 10.1534/g3.114.015784
http://www.g3journal.org/content/5/5/931.full
Cristy Gelling is a science writer, lapsed yeast geneticist, and former Communications Director at the GSA.
View all posts by Cristy Gelling »Read more in
-

Thank you, GSA community!
Thank you for being a member of the Genetics Society of America! As GSA’s current president, I am writing to tell you about Society projects and initiatives that we hope you will find useful in advancing your science and your career. Scientific research is a collaborative and exciting endeavor. Scientific societies like GSA exist to…
-

Where are they now? Rosalind Franklin Young Investigator Award recipients share updates on their research
Rosalind Franklin Young Investigator Award applications are open–make sure you submit your application or nomination of a colleague by September 30, 2024.
-

University of Minnesota researchers map genome of the last living wild horse species
The study, published in G3: Genes|Genomes|Genetics, is part of larger conservation efforts to save Przewalski’s horse.
-

Congratulations to the Spring 2024 DeLill Nasser Awardees!
GSA is pleased to announce the recipients of the DeLill Nasser Award for Professional Development in Genetics for Spring 2024! Given twice a year to graduate students and postdoctoral researchers, DeLill Nasser Awards support attendance at meetings and laboratory courses. The award is named in honor of DeLill Nasser, a long-time GSA supporter and National Science Foundation…
-

Carolyn Damilola: an NFS Rising Scientist on a lifelong quest to learn more
Carolyn Damilola is an NFS Rising Scientist from Nigeria doing respiratory system research and paving the way for scientists from underrepresented communities through mentorship.
-

What does a good microgrant proposal look like?
Members of the Microgrant Review Committee share their tips for a successful proposal.
-

The first piece of the facial recognition puzzle
New research in GENETICS gives a first peek at the molecular pathway involved in recognizing faces.
-

New Senior Editor Amy MacQueen joins GENETICS
A new senior editor is joining GENETICS in the Genome Integrity and Transmission section. We’re excited to welcome Amy MacQueen to the editorial team.
-

Block party on the zebrafish sex chromosome
Research in G3 identifies a gene regulatory block of the zebrafish genome responsible for overseeing the maternal-to-zygotic-transition.
-

Unraveling the mysteries of duckweed: epigenetic insights from Spirodela polyrhiza
Research published in G3 offers insight into the impact of DNA methylation on clonal propagation in asexually reproducing plants.
-

A microbiologist’s quest to understand CRISPR in bacterial self-defense
2024 Genetics Society of America Medal recipient Luciano Marraffini determined how CRISPR-Cas systems destroy genetic targets with precision, paving the way for gene editing technology development.
-

Unlocking mysteries of trait and disease heritability in dogs
2024 Edward Novitski Prize recipient Elaine Ostrander, a pioneer of the domestic dog model, discovered numerous genes affecting dog size, morphology, behavior, and disease susceptibility—many of which have relevance in humans.
-

GSA and collaborators Personal Genetics Education & Dialogue and Reclaiming STEM Institute launch NSF-funded BIO-LEAPS project to support culture change in genetics
We are thrilled to announce that the Genetics Society of America (GSA) is collaborating with the Personal Genetics Education & Dialogue (PGED) based in the Department of Genetics at Harvard Medical School, and the Reclaiming STEM Institute (RSI) on a Leading Culture Change Through Professional Societies of Biology (BIO-LEAPS) grant from the U.S. National Science…
-

Daman Saluja: Navigating Science and Policy in India
In the Paths to Science Policy series, we talk to individuals who have a passion for science policy and are active in advocacy through their various roles and careers. The series aims to inform and guide early career scientists interested in science policy. This series is brought to you by the GSA Early Career Scientist…
-

A fly geneticist’s journey into discovering rules of organ development
2024 George W. Beadle Award recipient Deborah Andrew discovered new genes and pathways in Drosophila salivary gland organogenesis. Now, her work can help optimize cell secretion in therapeutic applications and fight malaria.
-

Małgorzata Gazda: How receiving the DeLill Nasser Award helped her land her dream job
Have you ever experienced an event that changes the course of your life, or in this case, your career? Małgorzata (Gosia) Gazda is Assistant Professor at the University of Montreal and in 2022, she received the DeLill Nasser Award for Professional Development in Genetics, which she used to attend and present at the 2022 Population,…
-

Hongyu Zhao joins GENETICS as new Senior Editor
A new senior editor is joining GENETICS in the Statistical Genetics and Genomics section. We’re excited to welcome Hongyu Zhao to the editorial team.
-

GSA Member Julio Molina Pineda Receives DeLill Nasser Award, Shines at TAGC 2024
“At any career stage, the GSA membership is an amazing investment for any genetics professional!” Julio Molina Pineda is a PhD Candidate in Cell and Molecular Biology and a Research Assistant at the University of Arkansas, and a Doctoral Academy Fellow at the Lewis Lab. In 2023, Julio was awarded the DeLill Nasser Award for…
-

In Memoriam: Ellsworth Herman Grell (1932–2023), a pioneer of Drosophila genome engineering and annotation
Ellsworth (Ed) Grell blessed the Drosophila community through three enduring legacies: as a pioneer of chromosome mechanics, as a primary organizer and synthesizer of genetic knowledge in Drosophila, and as a graceful mentor to those fortunate to have known him personally. Ed grew up in rural Nebraska, completed his undergraduate studies at Iowa State, and…
-

Congratulations to the #Fungal24 Poster Award winners!
We are pleased to announce the recipients of the GSA Poster Awards for posters presented at the 32nd Fungal Genetics Conference! Undergraduate and graduate student members of GSA were eligible for the awards, and a hard-working team of judges made the determinations. Congratulations to all! Felicia Ebot Ojong, The University of Georgia My research is focused…
-

Poster presentation tips for TAGC 2024
You’ve been selected to present a poster at The Allied Genetics Conference 2024 in March—you’ve celebrated, made plans to attend, now what? This is an exciting opportunity to showcase your research and engage with fellow members of the genetics community, so you want to make sure you’re prepared. We wanted to offer you some tips…
-

Maximize your TAGC 2024 experience
A guide to all that National Harbor & DC have to offer Are you joining us for The Allied Genetics Conference 2024 in March? Make the most of your #TAGC24 experience in National Harbor! We know the science will keep you busy, but you deserve to unwind and have some fun, so we’ve curated a…
-

Early Career Leadership Spotlight: Sarah Petrosky
We’re taking time to get to know the members of the GSA’s Early Career Scientist Committees. Join us to learn more about our early career scientist advocates. Sarah PetroskyMultimedia SubcommitteeUniversity of Pittsburgh Research Interest I am interested in understanding adaptation that has been happening recently in populations by dissecting the ways that genes underlying an adaptation…
-

TAGC 2024 Early Career Award Winners
GSA is pleased to announce the winners of the early career awards presented at The Allied Genetics Conference 2024. These awards are specific to particular TAGC communities and recognize early career scientists’ outstanding work on their respective research organisms. The awardees will present their talks in keynote sessions at TAGC 2024. Don’t miss the opportunity…
-

Preeminent geneticists recognized with revamped GSA Awards
In 2022, GSA’s Board of Directors launched an audit to review the five major awards conferred by the Society. Today, we are thrilled to announce the recipients of the reimagined GSA Awards, including the new Genetics Society of America Early Career Medal. The scientists honored this year are recognized by their peers for their outstanding…
-

Fly Board funds outreach programs to spread the word about Drosophila research
In 2020, the Fly Board voted to use part of its reserve fund to support efforts to increase trainee participation as well as equity and diversity in the Drosophila community. An awards committee decides how the money will be spent each year, and from 2020–2022, the committee posted a very broad call for applications from…
-

New members of the GSA Board of Directors: 2024–2026
We are pleased to announce the election of four new leaders to the GSA Board of Directors: 2024 Vice President/2025 President Brenda Andrews Professor, University of Toronto It’s an honor to continue my association with the Society by serving as Vice President of the Board of Directors. I have broad knowledge of the ongoing activities…
-

Lost in translation: Finding genetic differences with greater confidence
Researchers benchmark widely used variant-calling tools to improve the accuracy of genomic analyses in laboratory mice
-

Congratulations to the Spring 2026 DeLill Nasser Award recipients!
Twice each year, the DeLill Nasser Awards for Professional Development support graduate students and postdoctoral researchers as they pursue opportunities to advance their research, expand their skills, and connect with the genetics community. Meet this season’s recipients and learn about the exciting research they’re leading.
-

Landing a faculty position: Jazlyn Mooney
Interviews from newly appointed faculty members shed light on the path to landing a faculty position.