

Today’s guest post was contributed by Maria Costanzo of Stanford University. She has been a biocurator since before the term was coined and has contributed to genome database projects for a variety of fungi. The views expressed are her own. Follow her on Twitter: @mariaccostanzo.
When someone asks what I do for a living, my answer is usually met with a blank stare. Biocuration is a rare and seemingly arcane occupation.
In many ways, curation of biological data is much like traditional curation of museum collections. Museum curators start with a collection of objects, and so do biocurators. While museum curators might select fossils or pottery shards, biocurators sift through facts—pieces of data—that are published in scientific journals.
Biocurators collect, organize, interpret, and display biological data, a task that is becoming more and more necessary. Genome sequences, protein functions, mutant phenotypes, gene expression data, and much more are published every day. It’s an impossible task for any individual scientist to keep up with so many papers. Biocuration makes it possible for researchers to access, synthesize, and analyze all these different types of information. It’s slowly becoming recognized as an occupation, and biocurators now have their own professional organization, the International Society for Biocuration.
Although researchers know of biocurators’ existence (because they use the databases that we maintain), most are still unaware of what it takes to get their data into those databases. When I go to conferences to represent the Saccharomyces Genome Database (SGD), where I’ve worked for more than a decade, one of the most frequent questions I’m asked is “So, what do you actually DO?”
First, curators have to find papers that are relevant to our particular curation effort. It’s relatively easy to identify articles on budding yeast, because most authors who publish on S. cerevisiae mention the species. It also helps that S. cerevisiae gene nomenclature is uniform and adheres to standards agreed upon by the research community and mediated by SGD.
For biocurators working on species other than S. cerevisiae, even identifying the right papers to curate can be a tough task. Researchers publishing on mammalian genes, especially, have a tendency to mix and match species in their experiments, and sometimes they don’t clearly identify the species of origin of the genes they study. Plus, gene naming is not nearly as uniform in some other species as it is in budding yeast. As an extreme example, the fruit fly Andorra gene is also known as “and”—try searching for papers about the and gene!
Once they have a set of relevant papers in hand, biocurators must decide which facts to select from those papers, just as museum curators select representative artifacts to display. The type of facts differs somewhat between databases: while some basic information, such as protein function or localization, is relevant to any organism, other biological phenomena, such as alternative mRNA splicing or regulatory microRNAs, are known only in certain species.
Biocurators need to record each fact so that it is traceable both to specific entities (e.g., a gene or protein, with a specific sequence, from a specific strain of a specific organism) and to the fact’s source (the publication). The way in which the fact is recorded matters too. Rather than just jotting down notes, biocurators have created “controlled vocabularies” that use specific phrases to express biological facts across genomes and even across organisms. The most well-known controlled vocabulary is the Gene Ontology (GO), which is used to express the molecular functions, biological roles, and subcellular locations of gene products from dozens of different species.
Next, biocurators face yet another decision: how to present the information on the web pages of the database. Museum curators engage visitors by designing visually attractive, easily understandable displays, and it’s not too different for biocurators. We’re helped in this effort by talented programmers and web designers, but a lot of scientific judgment goes into planning how to organize and display biological information so that it’s easy for scientists to search for and retrieve the results they need.
Now the analogy to museum curators breaks down, as the other parts of a biocurator’s job don’t have direct equivalents in the museum. Because visitors to a biological database are often looking for very specific pieces of information—about a gene, a pathway, a part of the cell—having efficient search tools is critical. Again, both programming and scientific expertise goes into designing these searches.
Finally, while museums employ guards to make sure that visitors don’t take anything with them when they leave, an important part of a biocurator’s job is to make it easy for visitors to take away large quantities of information. Research scientists need to be able to download data. So biocurators need to make sure to collect significant datasets and make them easily accessible, and also to load data into versatile data warehouses that allow custom queries, such as the InterMine software. SGD’s instance of InterMine, called YeastMine, contains virtually all of the S. cerevisiae data found in SGD and allows researchers to slice and dice it in countless ways. Being able to play with the existing data helps them to develop the hypotheses that will drive the next series of experiments, generating more data that will be published and incorporated into databases (see figure below).
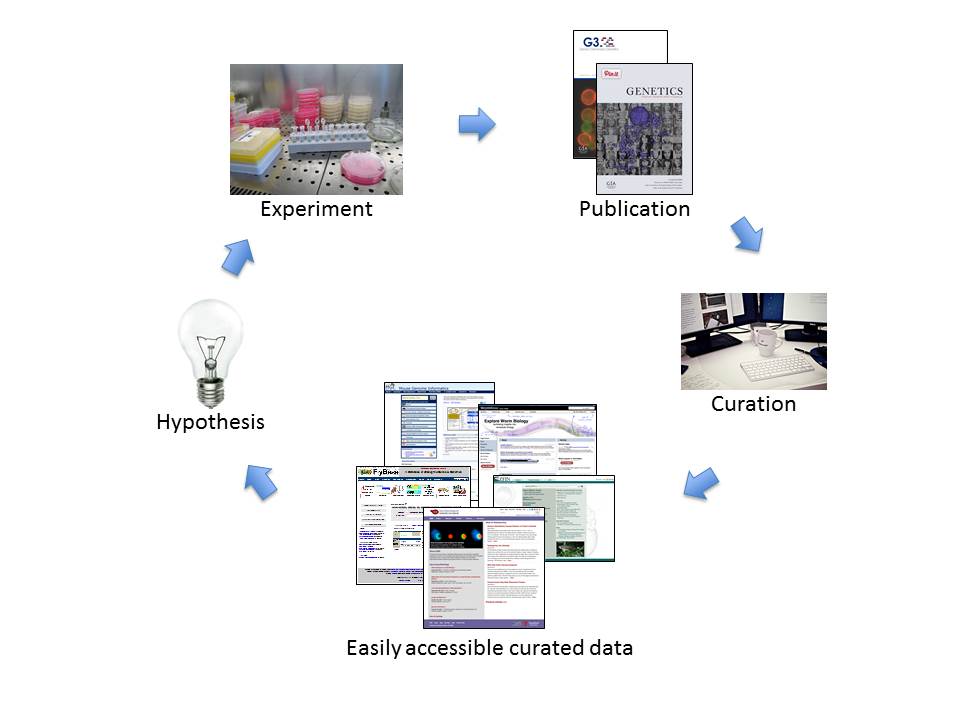
Researchers form hypotheses, design experiments to test those hypotheses, and publish the results. Biocurators then extract defined types of data from the publications, organize the information, and make it easily accessible in online databases. Using the databases, researchers can analyze, browse, and download the curated data, generating insights that allow them to formulate new hypotheses and start the cycle again. (Image Credit: Maria Costanzo)
Circling back to the original question, the simple answer to what biocurators actually DO, is this: They read a lot. Think a lot. Draw on their PhD-level scientific training to understand and interpret experimental results. Track down missing pieces of information to solve puzzles. Put everything in its proper place.
At times, for example when navigating the finer details of ontology structure or when confronting a list of hundreds of genes whose annotations need to be reviewed, the work can feel esoteric and isolated—a monkish discipline, like hand-copying the pages of an illuminated manuscript. But most of the time, it is exhilarating to have a broad view of the newest discoveries in your field and to have the opportunity to facilitate research all over the world. And when you attend a conference, the grateful scientists who rely on and appreciate your database can make you feel like a celebrity. Biocuration is a great way for those of us who don’t want to spend our careers standing at a lab bench to use our expertise and contribute to scientific progress.
The top 5 things researchers can do to ensure their work is curated accurately 1. Clearly identify the organism and the principal genes/proteins in the title or abstract of your paper. The initial screen that biocurators use to find relevant literature often searches titles and abstracts but not the full text of papers. 2. Provide accession numbers, standard names, and/or references for all the biological entities in your publication: the organism, strain or sub-strain, gene or protein sequence. Use accepted, official gene nomenclature. Don’t re-name a gene in your paper without consulting nomenclature authorities for your organism. Is it really worth choosing your own new gene name if it means that no one can figure out which gene you’ve characterized, and if your work isn’t linked correctly in databases? 3. Provide supplementary data in a format accessible to biocurators who may be using the files to load data: tab-delimited text or Excel files rather than PDFs. Please use a format that allows for the data to be easily reused and manipulated. 4. Write clearly. Biocurators are experts in their fields—typically, PhD-level scientists—but they are not specialists in every sub-discipline. Clear writing with a minimum of jargon will benefit all readers of your work! 5. Stay in touch. When you use your favorite database, remember that there are people behind the curation. If you have new data coming down the pipeline, or if you see something amiss in the database, let biocurators know. They’ll be happy to hear from you! |
| The views expressed in guest posts are those of the author and are not necessarily endorsed by the Genetics Society of America or its employees. |
Guest posts are contributed by members of our community. The views expressed in guest posts are those of the author(s) and are not necessarily endorsed by the Genetics Society of America. If you'd like to write a guest post, e-mail communications@genetics-gsa.org.
View all posts by Guest Author »Read more in
-

Thank you, GSA community!
Thank you for being a member of the Genetics Society of America! As GSA’s current president, I am writing to tell you about Society projects and initiatives that we hope you will find useful in advancing your science and your career. Scientific research is a collaborative and exciting endeavor. Scientific societies like GSA exist to…
-

Where are they now? Rosalind Franklin Young Investigator Award recipients share updates on their research
Rosalind Franklin Young Investigator Award applications are open–make sure you submit your application or nomination of a colleague by September 30, 2024.
-

University of Minnesota researchers map genome of the last living wild horse species
The study, published in G3: Genes|Genomes|Genetics, is part of larger conservation efforts to save Przewalski’s horse.
-

Congratulations to the Spring 2024 DeLill Nasser Awardees!
GSA is pleased to announce the recipients of the DeLill Nasser Award for Professional Development in Genetics for Spring 2024! Given twice a year to graduate students and postdoctoral researchers, DeLill Nasser Awards support attendance at meetings and laboratory courses. The award is named in honor of DeLill Nasser, a long-time GSA supporter and National Science Foundation…
-

Carolyn Damilola: an NFS Rising Scientist on a lifelong quest to learn more
Carolyn Damilola is an NFS Rising Scientist from Nigeria doing respiratory system research and paving the way for scientists from underrepresented communities through mentorship.
-

What does a good microgrant proposal look like?
Members of the Microgrant Review Committee share their tips for a successful proposal.
-

The first piece of the facial recognition puzzle
New research in GENETICS gives a first peek at the molecular pathway involved in recognizing faces.
-

New Senior Editor Amy MacQueen joins GENETICS
A new senior editor is joining GENETICS in the Genome Integrity and Transmission section. We’re excited to welcome Amy MacQueen to the editorial team.
-

Block party on the zebrafish sex chromosome
Research in G3 identifies a gene regulatory block of the zebrafish genome responsible for overseeing the maternal-to-zygotic-transition.
-

Unraveling the mysteries of duckweed: epigenetic insights from Spirodela polyrhiza
Research published in G3 offers insight into the impact of DNA methylation on clonal propagation in asexually reproducing plants.
-

A microbiologist’s quest to understand CRISPR in bacterial self-defense
2024 Genetics Society of America Medal recipient Luciano Marraffini determined how CRISPR-Cas systems destroy genetic targets with precision, paving the way for gene editing technology development.
-

Unlocking mysteries of trait and disease heritability in dogs
2024 Edward Novitski Prize recipient Elaine Ostrander, a pioneer of the domestic dog model, discovered numerous genes affecting dog size, morphology, behavior, and disease susceptibility—many of which have relevance in humans.
-

GSA and collaborators Personal Genetics Education & Dialogue and Reclaiming STEM Institute launch NSF-funded BIO-LEAPS project to support culture change in genetics
We are thrilled to announce that the Genetics Society of America (GSA) is collaborating with the Personal Genetics Education & Dialogue (PGED) based in the Department of Genetics at Harvard Medical School, and the Reclaiming STEM Institute (RSI) on a Leading Culture Change Through Professional Societies of Biology (BIO-LEAPS) grant from the U.S. National Science…
-

Daman Saluja: Navigating Science and Policy in India
In the Paths to Science Policy series, we talk to individuals who have a passion for science policy and are active in advocacy through their various roles and careers. The series aims to inform and guide early career scientists interested in science policy. This series is brought to you by the GSA Early Career Scientist…
-

A fly geneticist’s journey into discovering rules of organ development
2024 George W. Beadle Award recipient Deborah Andrew discovered new genes and pathways in Drosophila salivary gland organogenesis. Now, her work can help optimize cell secretion in therapeutic applications and fight malaria.
-

Małgorzata Gazda: How receiving the DeLill Nasser Award helped her land her dream job
Have you ever experienced an event that changes the course of your life, or in this case, your career? Małgorzata (Gosia) Gazda is Assistant Professor at the University of Montreal and in 2022, she received the DeLill Nasser Award for Professional Development in Genetics, which she used to attend and present at the 2022 Population,…
-

Hongyu Zhao joins GENETICS as new Senior Editor
A new senior editor is joining GENETICS in the Statistical Genetics and Genomics section. We’re excited to welcome Hongyu Zhao to the editorial team.
-

GSA Member Julio Molina Pineda Receives DeLill Nasser Award, Shines at TAGC 2024
“At any career stage, the GSA membership is an amazing investment for any genetics professional!” Julio Molina Pineda is a PhD Candidate in Cell and Molecular Biology and a Research Assistant at the University of Arkansas, and a Doctoral Academy Fellow at the Lewis Lab. In 2023, Julio was awarded the DeLill Nasser Award for…
-

In Memoriam: Ellsworth Herman Grell (1932–2023), a pioneer of Drosophila genome engineering and annotation
Ellsworth (Ed) Grell blessed the Drosophila community through three enduring legacies: as a pioneer of chromosome mechanics, as a primary organizer and synthesizer of genetic knowledge in Drosophila, and as a graceful mentor to those fortunate to have known him personally. Ed grew up in rural Nebraska, completed his undergraduate studies at Iowa State, and…
-

Congratulations to the #Fungal24 Poster Award winners!
We are pleased to announce the recipients of the GSA Poster Awards for posters presented at the 32nd Fungal Genetics Conference! Undergraduate and graduate student members of GSA were eligible for the awards, and a hard-working team of judges made the determinations. Congratulations to all! Felicia Ebot Ojong, The University of Georgia My research is focused…
-

Poster presentation tips for TAGC 2024
You’ve been selected to present a poster at The Allied Genetics Conference 2024 in March—you’ve celebrated, made plans to attend, now what? This is an exciting opportunity to showcase your research and engage with fellow members of the genetics community, so you want to make sure you’re prepared. We wanted to offer you some tips…
-

Maximize your TAGC 2024 experience
A guide to all that National Harbor & DC have to offer Are you joining us for The Allied Genetics Conference 2024 in March? Make the most of your #TAGC24 experience in National Harbor! We know the science will keep you busy, but you deserve to unwind and have some fun, so we’ve curated a…
-

Early Career Leadership Spotlight: Sarah Petrosky
We’re taking time to get to know the members of the GSA’s Early Career Scientist Committees. Join us to learn more about our early career scientist advocates. Sarah PetroskyMultimedia SubcommitteeUniversity of Pittsburgh Research Interest I am interested in understanding adaptation that has been happening recently in populations by dissecting the ways that genes underlying an adaptation…
-

TAGC 2024 Early Career Award Winners
GSA is pleased to announce the winners of the early career awards presented at The Allied Genetics Conference 2024. These awards are specific to particular TAGC communities and recognize early career scientists’ outstanding work on their respective research organisms. The awardees will present their talks in keynote sessions at TAGC 2024. Don’t miss the opportunity…
-

Preeminent geneticists recognized with revamped GSA Awards
In 2022, GSA’s Board of Directors launched an audit to review the five major awards conferred by the Society. Today, we are thrilled to announce the recipients of the reimagined GSA Awards, including the new Genetics Society of America Early Career Medal. The scientists honored this year are recognized by their peers for their outstanding…
-

Fly Board funds outreach programs to spread the word about Drosophila research
In 2020, the Fly Board voted to use part of its reserve fund to support efforts to increase trainee participation as well as equity and diversity in the Drosophila community. An awards committee decides how the money will be spent each year, and from 2020–2022, the committee posted a very broad call for applications from…
-

New members of the GSA Board of Directors: 2024–2026
We are pleased to announce the election of four new leaders to the GSA Board of Directors: 2024 Vice President/2025 President Brenda Andrews Professor, University of Toronto It’s an honor to continue my association with the Society by serving as Vice President of the Board of Directors. I have broad knowledge of the ongoing activities…
-

Policy changes are closing the door on the “American Dream”
The American Dream once promised that talent and hard work could open doors. For early career scientists, those doors are now closing. Research is being paused or studies outright canceled, funding delayed or completely pulled, and careers cut short—not because of bad science, but because of changing political priorities. Researchers are being forced to choose: leave science or leave the country. These setbacks send a clear message: the U.S. commitment to supporting the next generation of scientists is waning.
-

Congratulations to the Worm 2025 GSA Poster Award Recipients
We are pleased to announce the GSA Poster Award recipients from the 25th International Worm Meeting! Undergraduate and graduate student GSA members were eligible for these awards, and a hard-working team of judges made the determinations. Congratulations to all! Kehinde Joan Abayomi, Mount Desert Island Biological Laboratory Category: Gene Regulation & Genomics Poster title: “Transcriptome…
-

GENETICS Expands Primers Section
Beth De Stasio of Lawrence University will serve as Senior Editor and work with a newly formed team of six Associate Editors to expand the publication of Primers in GENETICS.